
Czy wyobrażasz sobie rozwijanie projektu bez repozytorium kodu? Ja teoretycznie tak – na początku swojej kariery zawodowej, przez pierwsze miesiące nie używaliśmy żadnego sposobu na wersjonowanie kodu. Najbardziej aktualna wersja znajdowała się na serwerze produkcyjnym (a przynajmniej miała się znajdować). Wszystko trwało do czasu (kwestia miesiąca, dwóch – nie pamiętam dokładnie), aż totalnie unieruchomiliśmy jeden z kluczowych projektów w firmie 🙂 Historia smutna, jednak prawdziwa.
Po ponad 9 latach od tego wydarzenia, repozytorium kodu jest ciąge must have. Tak na prawdę jest to jedna z pierwszych rzeczy które towarzyszą każdemu z nas przy uruchamianiu nowego projektu. Dlaczego więc ciągle po macoszemu traktujemy strukturę bazy danych? Przecież to również kod, mocno związany z naszą aplikacją. Nie zawsze code first jest wystarczający – czasem trzeba wygenerować bardzo specyficzne widoki. Dlaczego jedynie co widzę w repozytoriach to dump.sql? Czy jedna zmiana – np. dodanie kolumny do tabeli – musi pociągać za sobą drop database aby zaimportować na nowo dump.sql? Oczywiście, że nie! Są na to lepsze sposoby.
If you deploy version 2.0 of your application against version 1.0 of your database, what do you get? A broken application, that’s what. That’s why your database should always be under source control, right next to your application code. You deploy the app, and you deploy the database. Like peanut butter and chocolate, they are two great tastes that taste great together.
Sposobów na realizację wersjonowania bazy danych jest kilka (oczywiście pomijając sposób najbardziej popularny – dupny plik z dumpem aktualnej bazy ;)). Możemy wykorzystać prosty mechanizm który będzie odtwarzał jej stan na podstawie kolekcji plików SQL (np. w formacie 01_2017-05-18_12-50_createUserTabel.sql) lub też używając rozbudowanych narzędzi – Liquibase. W tym wszystkim chciałbym podkreślić jedną rzecz – ważne jest rozwiązanie problemu niż wybór konkretnego narzędzia. Liquibase jest świetny, ale w przypadku projektu Auditor, aż nadmiarowy. Dodatkowo wymaga Javy, czyli kolejnej zależności która musi zostać spełniona na serwerze uruchomieniowym. Zdecydowałem się na wybranie innego rozwiązania…
Phinx
Phinx idealnie wpasował się w kontekst projektu – napisany przy użyciu PHP, a co za tym idzie – instalacja z poziomu Composer oraz zapis migracji przy użyciu tego języka.
Możliwości rozwiązania opisane zostały na oficjalnej stronie, są to między innymi:
- tworzenie migracji bazodanowych przy użyciu języka PHP, zapewniając tym samym niezależność od zastosowanej bazy SQL oraz możliwość wersjonowania w repozytorium kodu,
- migracje „up” & „down”,
- łatwość uruchamiania,
- umożliwia zasilanie danymi początkowego stanu bazy,
- nie musisz przejmować się aktualnym stanem bazy, Phinx wie jakie migracje musi uruchomić,
- łatwość integracji z dowolną aplikacją,
- wsparcie dla najpopularniejszych baz relacyjnych.
Phinx posiada natywne wsparcie dla następujących baz danych:
- MySQL
- PostgreSQL
- SQLite
- Microsoft SQL Server
Instalacja
Najłatwiejszym sposobem na instalację Phinx jest wykorzystanie narzędzia Composer:
$: composer require robmorgan/phinx
Po prawidłowej instalacji, możliwy jest dostęp do narzędzia konsolowego. Wystarczy wykonać: vendor/bin/phinx. Za jego pomocą zinicjalizuję ustawienia wymagane przez Phinx:
$: vendor/bin/phinx init
Polecenie inicjalizacji Phinx utworzy plik phinx.yml w którym zdefinowana jest konfiguracja:
paths:
migrations: %%PHINX_CONFIG_DIR%%/db/migrations
seeds: %%PHINX_CONFIG_DIR%%/db/seeds
environments:
default_migration_table: phinxlog
default_database: development
production:
adapter: mysql
host: localhost
name: production_db
user: root
pass: ''
port: 3306
charset: utf8
development:
testing:
version_order: creation
Jak można zauważyć, konfiguracja Phinx nie jest skomplikowana. Nie wymaga specjalistycznej wiedzy, a jedynie podanie podstawowych informacji, tak aby narzędzie mogło nawiązać połączenie z bazą danych i pobrać listę dostępnych migracji. Umożliwia ustawienie:
- ścieżki do plików z migracjami (
paths > migrations), - ścieżki do plików z definicją jak powinien wyglądać początkowy stan bazy danych (
paths > seeds), - nazwy tabeli w której przechowywane będą informację na temat uruchomionych migracji (
environments > default_migration_table), - wybrania domyślnego połączenia z bazą danych (
environments > default_database), - podania danych do połączenia z bazą danych – możliwość skonfigurowania kilku różnych, np. względem środowiska uruchomieniowego (
environments).
Pozostaje jeszcze utworzyć strukturę folderów w której znajdować będą się migracje.
$: mkdir -p db/migrations db/seeds
Migracje (migration)
Migracją nazywamy zmianę struktur w których przechowywane są dane np. dodanie nowej tabeli, zmianę nazwy kolumny. Stworzenie nowej migracji, wymaga wykonania następującego polecenia:
$: vendor/bin/phinx create AddedPostTable
Phinx wygeneruje nowy plik w folderze db/migrations/. Plik z migracją zapisywany jest pod nazwą w formacie YYYYMMDDHHMMSS_my_new_migration.php. Następnym krokiem jest uzupełnienie migracji o akcje które mają zostać wykonane.
<?php
use Phinx\Migration\AbstractMigration;
class AddedPostTable extends AbstractMigration
{
public function up()
{
$this->table('post')
->addColumn('title', 'string', ['limit' => 200])
->addColumn('content', 'text')
->create();
}
public function down()
{
$this->table('post')
->drop();
}
}
Zaimplementowałem dwie metody. Pierwsza up() – czyli to co ma się wykonać w momencie uruchamiania migracji – w tym przypadku tworzona jest tabela post z dwoma kolumnami. Druga down() – czyli metoda która pozwala wycofać migrację – w tym przypadku tabela post jest usuwana.
Następnym krokiem jest uruchomienie migracji na wybranej bazie danych, zdefiniowanej w pliku konfiguracyjnym – development:
$: vendor/bin/phinx migrate -e development
Rezultatem jest nowa tabela w bazie danych o nazwie „post”. Phinx automatycznie zadbał o stworzenie auto increment primary key dla kolumny „id”.
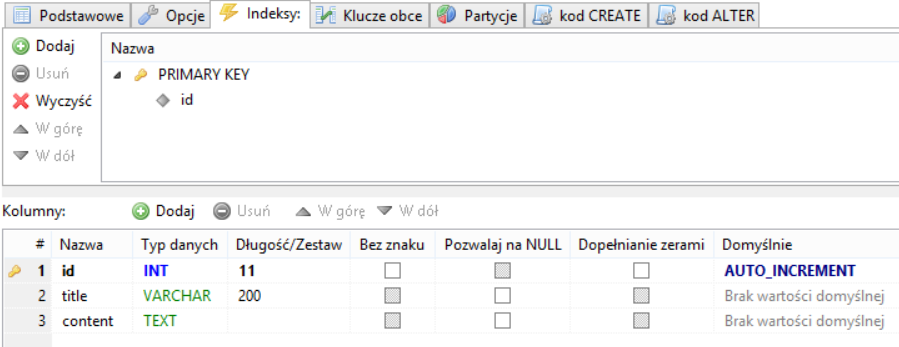
Oprócz zarządzania tabelą i kolumnami, możemy m.in definiować klucze zewnętrzne oraz indeksy na wybrane kolumny. Wszystkie te aspekty zostały w sposób wyczerpujący opisane w dokumentacji projektu – Phinx Writing Migrations.
Zasilanie danymi (seeds)
Każda struktura danych, prędzej czy później zostanie zasilona jakimiś danymi. W przypadku serwera testowego – mogą to być losowo wygenerowane dane (przy okazji polecam bibliotekę Faker), jeśli mówimy o serwerze produkcyjnym – mogą to być dane niezbędne do uruchomienia aplikacji.
Seed (będę używał angielskiego nazewnictwa, nie potrafię go przełożyć na język polski w sposób mnie zadawalający) może zawierać dane dla każdego typu środowiska. To od nas zależy w jaki sposób ułożymy sobie strukturę dla seeds. Mi zdarzało się tworzyć seeds które musiały wykonać się zawsze dla nowej instancji bazy danych (np. role użytkowników, podstawowe kategorie produktów) oraz dodatkowo takie które generowały dane testowe tylko w przypadku ich uruchomienia w środowisku testowym (np. testowe konta użytkowników z konkretnie przydzielonymi uprawnieniami). W tym przykładzie pominę jednak rozdzielanie typów seeds.
Stworzenie nowego seed przy użyciu narzędzia Phinx, wymaga wykonania następującego polecenia:
$: vendor/bin/phinx seed:create PostSeeder
W folderze db/seeds/ został utworzony plik PostSeeder.php. W nim umieszczam informacje które mają zostać dodane do bazy danych – dodaję pierwszy post, nadając mu tytuł oraz przykładową treść. Interfejs narzędzia Phinx i w tym przypadku jest bardzo przyjemny w użyciu.
<?php
use Phinx\Seed\AbstractSeed;
class PostSeeder extends AbstractSeed
{
public function run()
{
$this->table('post')
->insert([
'title' => 'First post!',
'content' => 'Lorem ipsum dolor sit amet, consectetur adipiscing elit.'
])->save();
}
}
Następnie należy uruchomić wykonanie wszystkich seeders:
$: vendor/bin/phinx seed:run
Lub tylko wybranych, podając nazwy seedów w parametrze:
$: vendor/bin/phinx seed:run -s PostSeeder -s OtherSeeder
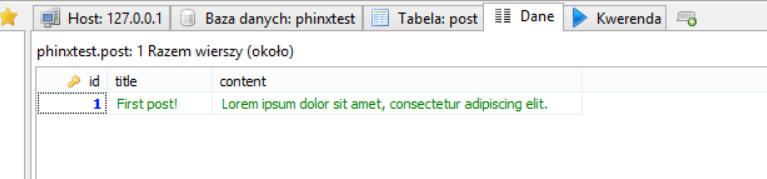
Po wykonaniu polecenia, tabela post zostanie uzupełniona o podane dane.
Podsumowanie
Warto dodać, że w ten sposób wszystkie zmiany struktury danych w bazie mogą być przechowywane w repozytorium kodu – przecież to normalny kod 🙂 Łatwo więc podejrzeć co się zmieniło w czasie, kto był odpowiedzialny za zmiany i w jakim kontekście one nastąpiły.
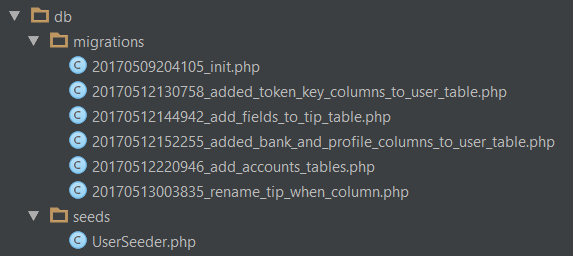
Powyższy screen obrazuje przykładowe zastosowanie Phinx w projekcie który realizowaliśmy na hackathonie CodING 2017. Tak, nazewnictwo mogło być nieco lepsze, uschematyzowane – jednak nie to było najważniejsze. Mieliśmy założenie – nauczyć się czegoś nowego (Phinx) oraz dostarczyć działającą aplikację. Migracje ułatwiły nam kwestię zmian na bazie danych – nie musieliśmy komunikować za każdym razem aby rozstawić bazę danych od nowa albo dodać nową kolumnę do istniejącej już struktury. Wystarczyło aby po zaciągnięciu nowych zmian z repozytorium, uruchomić polecenie vendor/bin/phinx migrate. Szybciej, łatwiej i przyjemniej.
Wpięcie narzędzia Phinx w projekt zajęło mi zaledwie kilka chwil. Dokumentacja jest czytelna i zwięzła, wszystko czego potrzebowałem byłem w stanie w niej odnaleźć. Prosty interfejs umożliwia realizację wszelkich niezbędnych operacji na strukturze bazy danych. Jeśli natomiast pojawi się jakiś nieobsłużony przypadek, w najgorszym razie można wywołać metodę execute($sql) przyjmującą jako argument zapytanie SQL. Proste narzędzie idealnie wpisujące się w projekt Auditor. Ciężko jest mi pisać o wadach rozwiązania, ponieważ jak na razie realizuje wszystkie moje potrzeby – jeżeli pojawią się problemy, na pewno opiszę je w ramach osobnego artykułu na blogu.






{kind=link}