
Co to jest Big Data? Czy problemy Big Data to problemy takie jak ja mam? Czy, mając dane w firmie, mogę jakoś wykorzystać narzędzia Big Data?
Big Data to popularny buzzword, który otwiera wiele drzwi, jeśli chodzi o możliwości zatrudnienia, ale z perspektywy biznesu służy do tworzenia nowych modeli biznesowych na bazie przetwarzania danych.
Zajmuję się budowaniem rozwiązań z zakresu Big Data już praktycznie 3 lata. Dziś mam zamiar pokazać Ci, czym jest Big Data i dlaczego jest to moim zdaniem kierunek przyszłościowy.
Dane są kluczowe
Czy korzystasz z któregoś z tych serwisów?
- YouTube
- Amazon
- Spotify
Przebywając w tych serwisach, zostawiasz bardzo dużo informacji o sobie, o swoim guście, o tym, co wspólnie ze znajomymi lubicie a czego nie. Te informacje są potrzebne np. reklamodawcom pod kątem tego, by wyświetlić Ci lepszą reklamę produktu, który może Ci się kiedyś podobał, a teraz jest na niego promocja.
Jeśli kiedyś zadałeś sobie pytanie: skąd Oni to wiedzą? Czy czytają moje e-maile? Siedzą mi w głowie? To odpowiedź brzmi: nie. Nie muszą. Wchodząc na różne strony, lajkując, oglądając filmy – robiąc wiele normalnych dla Ciebie czynności, zostawiasz bardzo ważny zestaw informacji, dzięki którym te firmy mogą funkcjonować.
Teraz przenieśmy ten eksperyment myślowy na wyższy poziom: jak myślisz, ile ludzi korzysta z tych serwisów w tym samym czasie? Ile danych zostawiasz, które z nich mogą być przydatne?
Jeśli odpowiedziałeś: sporo lub dużo, to jest to jak najbardziej prawidłowa odpowiedź. W grudniu z serwisu Facebook korzystało średnio 1,66 miliarda użytkowników dziennie. Do dziś przycisk like został wciśnięty 1,13 bilion razy.
To pokazuje skalę zjawiska, prawda? A to tylko jeden z wielu serwisów, który odwiedzasz.
By mieć pełnię wiedzy o Tobie, trzeba by było przechowywać wiedzę z kilku źródeł danych i odpowiednio nią zarządzać.
Nie wiadomo, które dane są użyteczne dzisiaj a które będą jutro, więc może warto gromadzić wszystko na wszelki wypadek.
I jeszcze, gdy będziemy uruchamiali przetwarzanie, to chcemy uzyskać odpowiedź w skończonym czasie.
Masakra… tyle rzeczy do ogarnięcia.
I tu z pomocą przychodzą narzędzia z rodziny Big Data, których celem jest właśnie praca z tego typu problemami.
Ładowanie danych ze źródeł. Przetwarzanie danych np. z wykorzystaniem algorytmów z rodziny uczenia maszynowego. Wizualizacja wyników w formie, która będzie przystępna.
Wszystko to, by móc lepiej zrozumieć. Przejdźmy więc dalej i przyjrzyjmy się czym jest Big Data i na jakie problemy odpowiada.
Big Data – czym tak naprawdę jest?
Załóżmy hipotetycznie, że masz firmę, która od wielu lat przechowuje dane na dysku pod biurkiem, albo w excelach. Nic z tym nie zrobi, bo nie wie co, nie wie czy może.
Nie jest to firma klasy Facebook czy Amazon, więc pytanie, czy Big Data się tu aplikuje.
To zależy.
Big Data jest związane z danymi. Tego powiązania nie unikniemy. Chodzi o to, by mając dane zweryfikować, czy jestem w stanie otrzymać odpowiedź na jakieś pytanie biznesowe. Jeśli nie, to co muszę zrobić, może powinienem brać dane z innych systemów, a może jeszcze nie mam sposobu, by to robić. Jeśli tak, to co muszę zrobić, by je otrzymać. Jakie narzędzia potrzebuję użyć?
To jest bardzo proste, ale podkreślam to z tego powodu, że mając częściowe, niekompletne dane, możemy nie otrzymać żadnej użytecznej odpowiedzi.
Kiepska odpowiedź może wynikać z tego, że niekompletne dane nie pozwolą na znalezienie prawidłowego wzoru lub – co gorsza – pokażą wzór nieprawidłowy
Świetnym przykładem była próba stworzenia nauczenia algorytmu aby rozpoznawał kubki. Niestety osoby, które dobierały materiał uczący dla algorytmu nie zauważyły, że zawiera on tylko zdjęcia kubków z uchem po tej samej stronie. Gdy pokazano mu zdjęcie kubka z uchem po przeciwnej stronie stwierdził, że to nie jest kubek.
Pytania, na które możemy szukać odpowiedzi to:
- Gdzie są największe straty w naszym przedsiębiorstwie?
- Jakie są przewidywania wydatków jeśli nastąpi kryzys?
- Jakie produkty podobne do tego, co ostatnio kupowałeś powinniśmy Ci polecić, by zwiększyć prawdopodobieństwo ich kupna?
- Jaki kolejny film zgodny z Twoim gustem i gustem Twoich znajomych możemy Ci polecić?
Jeśli dane, które do nas będą trafiać, są niepełne, nieczyste, zawierają błędy, to prawdopodobnie, jeśli nic z tym nie zrobimy, będziemy mieli błąd na wyjściu.
Garbage In – Garbage Out – to jedna z zasad pracy z danymi.
Big Data to nie jest deus ex machina rodem z filmów. To jest zbiór narzędzi, zbudowanych pod kątem konkretnych potrzeb i konkretnych sposobów użycia. Narzędzia, które były stworzone do przetwarzania danych o charakterze strumieniowym będą sobie gorzej radzić z przetwarzaniem dużych zbiorów danych.
Skoro już to sobie wyjaśniliśmy, to rzućmy okiem na model, który ułatwi nam zrozumienie problemów, z jakimi mierzyć się musi Big Data. Model ten nazywa się 4V: Volume, Variety, Velocity, Veracity.
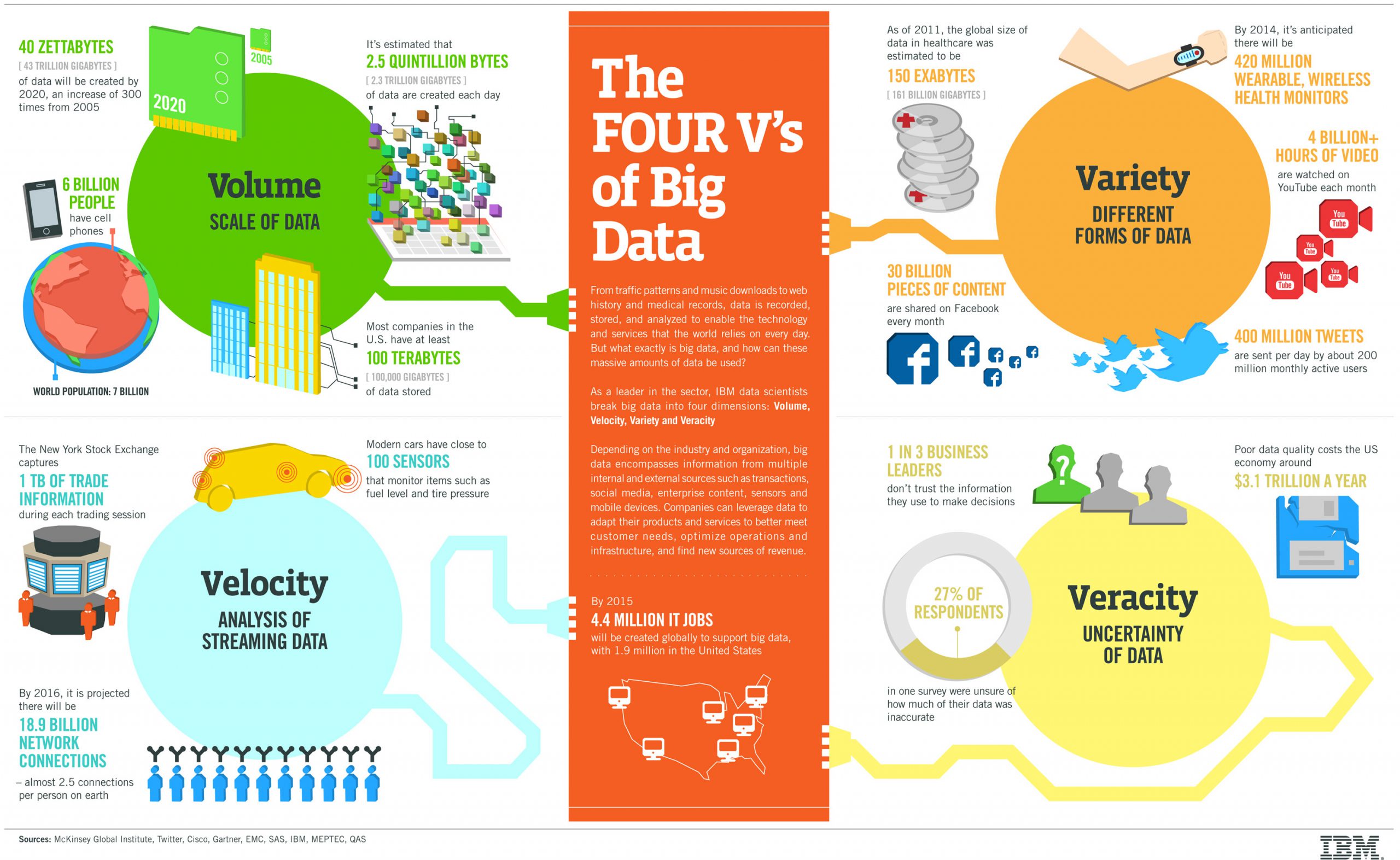
Źródło: https://sentai.eu/wp-content/uploads/2015/10/4-Vs-of-big-data-1.jpg
Big Data – czyli dużo danych
Z danych Facebook’a wynika, że każdego dnia oglądane jest 100 milionów godzin video. Przypomnij sobie, ile sam zostawiasz lajków i komentarzy. Ile profili przeglądasz dziennie.
Średnio 1,66 miliarda użytkowników dziennie może zachowywać się bardzo podobnie.
Z danych YouTube’a wynika, że wrzucane jest około 300 godzin video każdej minuty (https://merchdope.com/youtube-stats/). To, przy założeniu jakości video FHD i wielkości 1 minuty 50-68 MB, raptem 900 TB – 1,224 PB. Każdej minuty, a pewnie zauważyłeś, że ludzie wrzucają też inne formaty niż FHD.
Przy 30 milionowej armii ludzi oglądających filmiki na YT każdego dnia daje to bardzo ciekawe wyniki.

Źródło: https://2oqz471sa19h3vbwa53m33yj-wpengine.netdna-ssl.com/wp-content/uploads/2019/03/internet-minute-820.jpg
Czy jak mam mniej danych, to mój problem się kwalifikuje?
To zależy od tego, w jaki sposób je przetwarzasz i jakiej wielkości są to dane.
Silniki baz innego rodzaju, takie jak relacyjne (mylnie zwane SQL), czy NoSQL, do pewnego stopnia radzą sobie z dużymi wolumenami danych. Po przekroczeniu określonego dla danego narzędzia progu, przestają sobie z nimi radzić.
Jeśli wykorzystamy je w inny sposób niż zostały zaprojektowane, też się zakrztuszą.
Efekt? Nie dostaniemy odpowiedzi w tym stuleciu.
Rozwiązania Big Data są projektowane pod kątem operowania na dużych wolumenach( Terabajty, Petabajty) od samego początku. Narzędzia te są w stanie wykorzystać możliwości rozproszonych obliczeń z wykorzystaniem klastrów od samego początku.
Jest to też miecz obosieczny: jeśli masz mało danych, np. 50 mb, to uruchomienie klastra oraz obliczeń potrwa dłużej, niż zrobienie tego np.: ręcznie w kodzie w pythonie.
Przez “znacznie więcej” mam na myśli czas “od sekundy nawet do kilkunastu minut”. Narzędzia Big Data nie skalują się w dół tak samo dobrze, jak w górę. Niektóre z tych narzędzi po prostu się nie skalują wcale w dół.
Używanie dedykowanych narzędzi z rodziny Big Data opłaca się dopiero wtedy, gdy wejdziemy na duże przestrzenie danych lub te dane będą wielokrotnie wykorzystywane w obliczeniach. Większość narzędzi ma wbudowane możliwości skalowania w górę. Dorzucam dodatkowe jednostki, gdy jest to uzasadnione i obliczenia trwają krócej, jeśli da się te obliczenia wykonać równolegle.
Big Data to nie panaceum. Nie zawsze dorzucenie 50 komputerów zwiększa prędkość obliczeń 50 krotnie. W sumie to nie jest reguła liniowa. Zwiększ o x komputerów- będzie x razy szybciej. To wszystko zależy od obliczeń.
Big Data to duża ilość informacji do przechowywania i przetwarzania. Czasami, bo wiemy jak tą daną użyć, czasami, bo może się przyda a wiemy, że może być cenna.
Big Data – czyli strumień danych płynący z dużą prędkością
To chyba najlepiej obrazuje charakter danych. Strumień danych, który swobodnie płynie. Do którego wpływają różne mniejsze strumienie. Raz może być większy, raz mniejszy.
Skąd wynika ta zmienna charakterystyka strumienia? Z tego, że korzystamy w różny sposób. Nieregularne z różnych systemów.
Dam Ci kilka przykładów:
Facebook.
Wchodzisz regularnie 2-3 razy dziennie, czy gdy coś się pojawi?
Wrzucasz regularnie komentarze i zdjęcia, czy jak znajdziesz coś ciekawego?
Dane są silnie zależne od Twoich reakcji w tym wypadku.
Mogą np.: być bardzo sezonowe. Sklepy w obrębie świąt muszą być gotowe na wzrost zainteresowania. Ludzie kupują książki, prezenty i inne rzeczy. Tak samo zachowują się, jak będzie jakaś promocja np: cyber monday.
W tej sytuacji projektanci muszą być gotowi na to, by zwiększyć możliwości przyjmowania i/lub przetwarzania danych.
Czasowe zwiększenie możliwości, a potem zwolnienie zasobów, może okazać się dużym zbawieniem. Szczególnie dla działu, który zarządza budżetem.
Nie wszystkie strumienie jednak mają charakter zmienny. Są takie, które mogą mieć charakter stały. Weźmy dla przykładu sensory w samolotach, wodomierze lub liczniki prądu. Sensory są dobrym przykładem.
Jak popatrzymy na nie jednostkowo, to nie ma dużego problemu.
Ramka 50 Kb raz na sekundę. Przy 5,6 milionach użytkowników sieci.
Dane wysyłane są co 1 us z 100-150 sensorów w aucie wyścigowym.
W obu wypadkach chcemy mieć gwarancję, że żadna dana nam nie zniknie, bo chcemy mieć możliwość podjęcia istotnych decyzji. Decyzji, od których może zależeć nasza wygrana w wyścigu F1, albo awaria transformatora, który w momencie, w którym wszyscy pracują z domu, może po prostu wymagać szybszej wymiany.
Drugi aspekt Big Data, który należy uwzględnić, to to, w jaki sposób dane się pojawiają w czasie i jaki mają charakter.
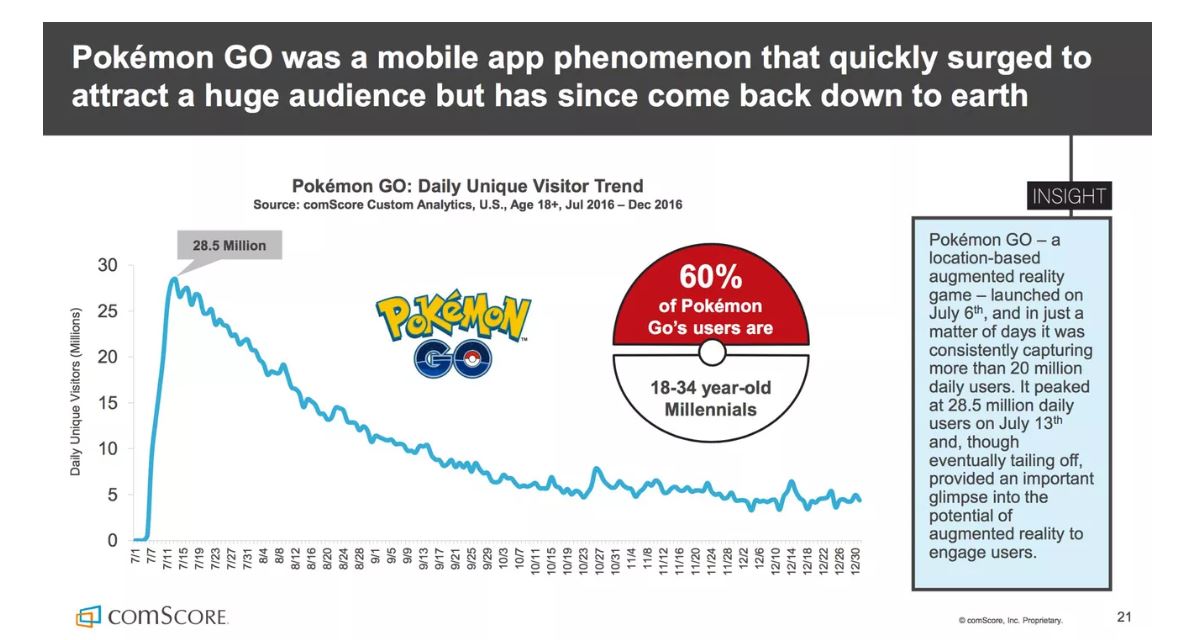
Źródło: https://1z1euk35x7oy36s8we4dr6lo-wpengine.netdna-ssl.com/wp-content/uploads/2017/08/Pokemon-Go-July-Dec-16.jpg
Big Data – czyli różnorodność formatów danych
Kto ma Facebooka na PC, telefonie i tablecie? Ręka do góry.
Kto korzysta z Youtuba w przeglądarce stacjonarnej, a kto w aplikacji natywnej na smartfonie? Ręka do góry.
Dobra- możecie opuścić, ale w tym tkwi problem i zarazem wyzwanie. Różne aplikacje, różne formaty, różne sposoby komunikacji. Różny ślad, który zostawiasz.
Nie ma jednego standardowego formatu. Każda aplikacja zapisuje dane w inny sposób.
Tweety wyglądają inaczej. Mają inne informacje niż polajkowany post na FB.
Dane mogą mieć strukturę, mogą jej nie mieć. Mogą mieć pola, mogą nie mieć.
Idea jest taka: nieważne. Nie weryfikujemy w trakcie zapisu. Zasada jest prosta – pchasz na łopatę i do wiadra.
Problemami z danymi zajmiemy się w trakcie przetwarzania. Ważne, by można było naraz pracować z JSON, XML oraz jakimikolwiek, które mogą się znacznie różnić między sobą i w obrębie tego samego źródła danych.
Bo dziś może być to liczba gwiazdek, a jutro procent 🙂
Spójność danych na etapie zapisu. Znowu ważne, żeby niczego nie stracić.
Big Data – czyli pewność danych
Nie mamy 100% pewności, że to, co jest dostępne, jest pewne. Z powodu niskiej jakości danych corocznie firmy w US tracą około 3,1 miliarda dolarów.
Czasami niektóre rzeczy robimy poważnie, czasami dla kawału, co też powoduje, że nie wszystko, co znajdziesz o danej osobie, musi być do końca uwzględnione. Gdyby tak było, to bym do końca życia musiał słuchać Barbie Girl zespołu Aqua, którą ktoś mi zapętlił, gdy poszedłem na urlop, przez co Spotify myślał, że słucham non stop tego samego utworu 7 dni/24h.
Dane mogą zawierać także błędy, wynikające z natury urządzeń pomiarowych, ludzkich błędów np.: błędnie wprowadzona dana lub subiektywna ocena.
Jest wiele powodów, dla których niektóre źródła lub poszczególne dane mogą budzić więcej lub mniej zaufania i z tym także trzeba sobie poradzić.
Czy chcieć odpowiedź teraz czy chcieć odpowiedź kiedyś
o jest ostatni aspekt, który dzisiaj poruszę. Otrzymanie rekomendacji po kliknięciu w zakup na bazie danych z ostatnich 300 lat, od grupy 8,6 miliardów ludzi jest raczej niemożliwe do obliczenia w ciągu sekundy. Raczej, bo może czytasz ten tekst, kiedy wynaleziono już odpowiednie narzędzia, albo komputery kwantowe o 8K Qbitów, które z duża dozą prawdopodobieństwa odpowiedzą na to pytanie.
Ważne jest to, że są pewne ograniczenia przy wykonywaniu przetwarzania. Tak jak wcześniej wspomniałem, można do pewnego stopnia skalować (dorzucać moc obliczeniową), ale nie ma gwarancji optymalizacji czasowej w nieskończoność. Zależy to od tego, jak to przetwarzamy oraz jakimi narzędziami. Skalowanie kosztuje. W chmurze dorzucasz dodatkowy zasób, natomiast w rzeczywistych infrastrukturach (sorry wiem, chmura to też fizyczna infrastruktura, ale gdzieś dalej) musisz dorzucić/wypożyczyć dodatkowy serwer. To kosztuje.
Big Data to także myślenie o wymaganiach w zakresie optymalizacji czasowo-kosztowej. Oraz o tym, kiedy spodziewamy się odpowiedzi.
Wyobraź sobie, że zamawiasz książkę. Pojawia się kursor klepsydry i czekasz spokojnie 5h na rekomendacje. Nie brzmi to akceptowalnie, prawda? Rekomendacja jest przykładem czynności, która powinna się dziać szybko. Klikam i pojawia się kolejna książką, która lubią np: moi znajomi. Inny przykład to reakcja na informacje o potencjalnej awarii, która może nas kosztować miliony. Też chcemy wiedzieć o tym tak szybko jak to możliwe. W obu przypadkach raczej nikt nie spodziewa (lub obecnie nie jest to możliwe technicznie) by przetworzyć duże ilości danych pod kątem tych konkretnych potrzeb w czasie poniżej 100 ms. Raczej operację będą wykonywane na fragmencie, wycinku danych lub przygotowanych wcześniej prefabrykatach. Np: danych o użytkowniku lub urządzeniu.
Odmienne podejście możemy zastosować, gdy czas odpowiedzi nie jest ważny, a algorytmy wymagają czasu by kilkukrotnie np: przejrzeć dane w poszukiwaniu nietrywialnych wzorców. I tutaj przykładem może być indeksowanie zasobów sieci, uczenie algorytmów maszynowych. Te czynności mogą trwać kilka godzin, ale w czasie ich trwania nie zależy nam by dostać częściową odpowiedź. Możemy poczekać. Wyniki takiego przetwarzania można potem wykorzystać w pierwszym trybie.
Narzędzia Big Data są dostosowane do problemu, ale o tym wspomnę w kolejnym artykule.
Dziś warto zapamiętać, czym jest, a czym nie jest Big Data i o 4 istotnych aspektach takiego podejścia reprezentowanych przez 4V.
A wszystko po to by …
Nie chcę zabrzmieć cynicznie, ale Big Data to nie jest rocket science. Jego celem jest dostarczenie odpowiedzi na problemy biznesowe.
Nie chodzi o to, by patrzeć jak dane przepływają z miejsca A do miejsca B. Nie chodzi o to, by pokazywać, że Hadoop jest lepszy czy też Spark.
W ogólnym rozrachunku chodzi o to, by wspomóc proces podejmowania decyzji. Ułatwić diagnostykę nowotworów. Znaleźć wycieki wody, kradzieże prądu.
Dane są tylko środkiem do celu, a Big Data narzędziem, które zamienia dane w użyteczne informacje. Bez zaprezentowania danych przetworzonych w odpowiedni sposób, nikogo nie będzie obchodziło, że mój algorytm przetwarza wszystko w 30s. Ważny jest efekt końcowy.
Narzędzia Big Data pozwalają inaczej podejść do danych. Zmienić sposób myślenia o ich zmiennym charakterze. Chyba najważniejsze, to zacząć eksplorować możliwości jakie nam dają dane, które nas otaczają i szukać, co można usprawnić, gdzie możemy zaoszczędzić. Coś, co mogło nie być możliwe przez ograniczenia technologiczne.
Patrz na Big Data jako na pewną klasę nowych możliwości. Możliwości, które mają służyć przede wszystkim ludziom.





")
{kind=link}