
Awarie, błędy, wpadki – to wszystko na nas czyha w codziennej pracy. Możemy robić wszystko co tylko się da aby tego uniknąć, ale ostatecznie i tak prędzej czy później dopadną nas problemy na “produkcji”. Stanie się to albo z powodu naszej niewiedzy, błędów w zależnościach czy też awarii infrastruktury. Najważniejsze jest jednak aby wyciągać z tych sytuacji wnioski.
Opiszę historię gdzie awaria relacyjnej bazy danych Aurora w AWS sprawiła, że serwis z niej korzystający nie funkcjonował poprawnie przez pewien czas. Mimo, że mechanizm przywracania Amazona zadziałał jak należy to okazało się, że nie byliśmy gotowi na taką sytuację.
Incydent
Zanim przejdziemy do opisu awarii w skrócie chciałbym wypunktować jak przedstawia się stan systemu w celu łatwiejszego zrozumienia całości.
- w naszym systemie posiadamy architekturę rozproszoną gdzie jeden serwis odpowiada za dostęp do danych
- serwis uruchomiony jest w kilku instancjach
- dane przechowywane są w bazie danych typu PostgreSQL na chmurowym rozwiązaniu Amazon Aurora
- baza danych działa na kilku instancjach, gdzie jedna z nich jest odpowiedzialna za zapis, a reszta za odczyt
Co się wydarzyło?
W pewnym momencie podczas działania aplikacji zaczęły pojawiać się logi po nieudanej próbie zapisu do bazy danych: cannot execute INSERT in a read-only transaction. Pierwsze zerknięcie na te logi i pojawia się myśl “chyba wprowadziliśmy jakiegoś buga”.
Obserwuję jednak, że te logi zaczęły się pojawiać od jednego punktu w czasie i nie jest to związana data z żadnym wdrożeniem.
Schodzę więc z obserwacjami niżej, spoglądam na infrastrukturę i dostrzegam, że coś się wydarzyło po stronie AWSa. Instancja typu write padła, w wyniku czego nastąpiła promocja nowego writera spośród istniejących readerów.
Normalne zachowanie, wszystko zadziałało jak należy. Dlaczego więc wciąż pojawiają się błędy wspomniane wyżej? Czyżby aplikacja w żaden sposób na to nie zareagowała?
Load Balancer w Aurora RDS nie działa tak jak myślisz
Serwisy łączą się do bazy danych na podstawie dwóch endpointów (jeden do writera, drugi do readerów). Spodziewałbym się, że przed klastrem bazodanowym istnieje jakiś mechanizm typu Load Balancer, który odpowiednio rozdziela połączenia.
No i tak się właśnie dzieje. Ale z jednym małym szczegółem. Load Balancer działa tylko dla instancji typu “read-only”. Do instancji typu writer połączenie przypisywane jest na stałe.
W wyniku tego dochodzi do sytuacji, że po wystąpieniu awarii na klastrze bazodanowym serwis nadal próbuje używać instancji, która początkowo była writerem, ale teraz jest readerem.
Pozwól mi to przedstawić krok po kroku…
- instancja o numerze 0 jest writerem, a instancje o numerach 1, 2 i 3 readerami.
- dochodzi do awarii na instancji 0 (writer), mechanizm Failover dokonuje selekcji nowego writera spośród pozostałych instancji. Wybiera instancję o numerze 2.
- instancja 0 powraca do życia po krótkiej przerwie, jednak w roli readera
- aplikacja w ogóle nie zareagowała na tę sytuację i nadal traktuje instancję 0 jako writera
Rozwiązanie: Pozwól na awarię
Jeśli w aplikacji rozproszonej jakiś komponent ulega awarii możliwe jest zastosowanie rozwiązania wyłącznego restartu oprogramowania. Opisuje to wzorzec Pozwól na awarię (Let-it-crash) z książki Reactive Design Patterns.
Krótko mówiąc – jeśli aplikacja podczas działania napotka jakiś problem, np. związany z infrastrukturą, a implementacja jego obsługi jest nieproporcjonalnie droga w stosunku do zwykłego ponownego uruchomienia tej usługi – to dlaczego tego nie zrobić?
Uśmiercanie usług to nie grzech
W tym wypadku rozwiązanie to wpasuje się idealnie, ponieważ jedynym zadaniem tego serwisu jest operowanie na bazie danych (zapisywanie i odczytywanie). Jeśli w danym momencie staje się niemożliwe to po co został stworzony, to jaki jest sens utrzymywania go przy życiu?
Jeśli zarządzony zostanie restart aplikacji to całkiem szybko powinna ona wrócić do stabilnego stanu. Zakładając, że zależny system (w tym wypadku baza danych) już działa poprawnie. W historii opisywanej przeze mnie aplikacja przez dłuższy czas nie zauważyła zmian infrastruktury i przez to potencjalnie zostały zgubione niezbędne dane.
Czy da się mniej inwazyjnie?
Czy jest inny sposób na rozwiązanie takich problemów? Jakiś taki bardziej “elegancki”?
Myślę, że da się reagować na podobny błąd, zwalniać połączenie i nawiązywać je ponownie. Można, ale należy zadać sobie pytanie czy jest sens inwestować czas w tworzenie podobnych mechanizmów?
Po pierwsze będzie potrzebne więcej czasu na zaprojektowanie, zaimplementownie i przetestowanie różnych warunków. I jak zwykle wciąż istnieje ryzyko, że coś zostanie pominięte.
Jednym z założeń mikrousług jest działanie serwisów w większej liczbie niż jedna instancja. Dzięki temu można pozwolić sobie na swobodne wyłączanie poszczególnych instancji w zależności od potrzeby. W wyniku tego nie trzeba się obawiać restartu – jest to całkiem proste, a zarazem skuteczne rozwiązanie.
Jak to przetestować?
Obsługa błędów i zachowanie typu fail-safe, czyli takie gdzie aplikacja musi wiedzieć jak się zachować w momencie wystąpienia awarii musi zostać odpowiednio przetestowane. Jak tego dokonać? Najlepiej doprowadzając do kontrolowanej awarii. W zależności od typu awarii przeciw której planujemy się zabezpieczyć będzie to wymagało różnego działania.
Symulacja zachowania Aurora Failover
Opisywaną awarię w tym poście da się bardzo łatwo odtworzyć z poziomu konsoli AWS. W oknie zarządzania instancjami bazy wystarczy wybrać akcję “failover”…
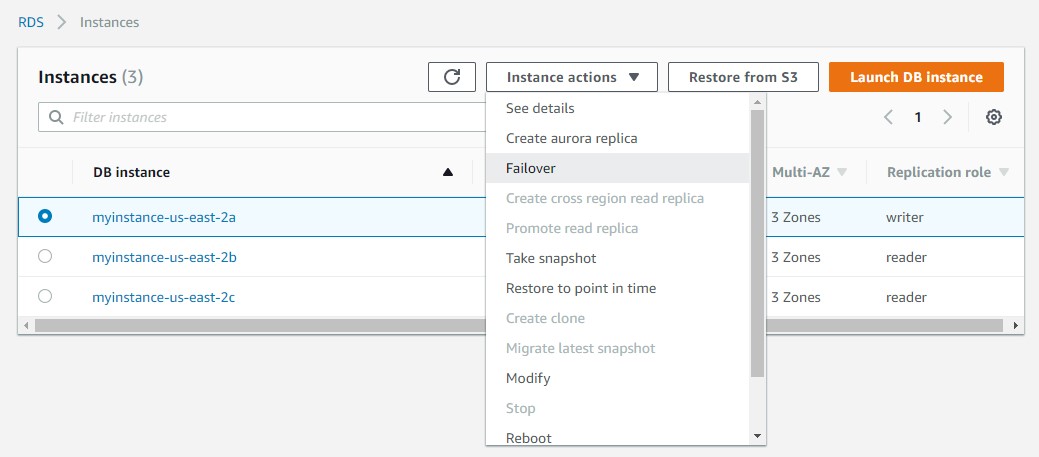
W tym momencie można obserwować jak na tę sytuację zareaguje aplikacja i ewentualnie dostosować jej zachowanie. Więcej o obsłudze tego typu akcji można znaleźć w oficjalnym artykule AWS.
Podsumowanie
W tym poście, na przykładzie prawdziwej awarii zaprezentowałem jedno z rozwiązań, które można stosować w systemach rozproszonych. Wzorzec “Pozwól na awarię” jest mechanizmem, który przewrotnie może pomóc utrzymać stabilność całego systemu. Przewrotnie, gdyż pozwalamy na zresetowanie działającego serwisu. Dokonujemy jednak tego aby wewnętrzna awaria jednej usługi nie wpłynęła negatywnie na inne.
Oczywiście jak to bywa z wzorcami – nie jest to panaceum na każdy typ awarii, który może się pojawić w naszych aplikacjach. Jest to raczej dedykowane do specyficznych sytuacji. Jak na przykład opisywana w tym poście awaria systemu bazodanowego.
Liczę, że historia opisana w tym poście pozwoli zwrócić również uwagę na to aby projektowane przez nas aplikacje nie były testowane tylko pod kątem wykonywania założeń biznesowych. Ważne jest dbanie o testowanie również wariantów, które nie mieszczą się w zwykłym “happy pathie”. Jeśli aplikacja będzie gotowa na przetrwanie awarii to z pewnością nie raz uratuje cię i twoją firmę przed dużymi problemami.






{kind=link}