
Skąd ten artykuł
Podczas live’a mówiącego o wzorcach projektowych (https://devenv.pl/wzorce-projektowe-ktore-uratowaly-nasze-projekty-live/ ) poproszono mnie, bym pokazał kod z prezentacji – przydatny zrost wzorców projektowych: metoda fabryczna ze strategią.
Niestety, oryginalny kod jest dość trudny do zrozumienia bez wiedzy o domenie, więc stworzyłem prosty przykład demonstrujący jak taki zrost działa i po co on jest.
W tym artykule pokażę dwa różne zrosty fabryki ze strategią:
- Typowy: if X -> zwróć strategię Y.
- Mniej typowy: na bazie danych z pliku wejściowego wybierz odpowiednią strategię budowania obiektu.
Przy okazji:
- Pokażę i wyjaśnię, co to jest Fabryka (i jak ją wykorzystać)
- Pokażę i wyjaśnię, co to jest Strategia (i jak ją wykorzystać)
Więc jeśli nie znacie dobrze tych wzorców projektowych, nie musicie zamykać taba w przeglądarce. Wyjaśnię w trakcie pokazywania kodu.
Gotowi?
Spójrzmy więc na domenę
Henstagram.
Nie możesz być największym kogutem w kurniku, jeśli nie prowadzisz swojego profilu na Henstagramie – miejscu, gdzie brutalnie oceniana jest jakość Twojego kurnika, Twoich kur oraz Twojej naturalnej charyzmy.
W tym okrutnym świecie Gladiatorów Henstagrama jesteś albo w pierwszej trójce, niezależnie od ilości uczestników, albo giniesz – czwarte miejsce się nie liczy.
Dla pierwszych trzech gladiatorów sława i nagrody pieniężne, dla pozostałych – robienie zdjęć kurom i sprzedawanie tych zdjęć by dostać zupę w proszku. A kupują zdjęcia z litości.
Czy masz wolę twardą niczym dziób koguci by dołączyć do świata HenstagramWars?
Każdy gladiator ma Imię oraz trzy cechy:
- Jakość kury
- Jakość kurnika
- Charyzma
I sędziowie będą oceniać na bazie tych cech którzy z naszych gladiatorów zasługują na podium.
Co zatem mamy do dyspozycji?
Mamy więc napisaną na szybko aplikację w C# (dokładniej: konsolowa C# .NET Core 3.1), która:
- Pobiera dane wejściowe o gladiatorach Henstagrama („Competitors”) z plików tekstowych
- Dane o gladiatorach mogą być w jednym z wielu formatów / schematów („Schema”)
- Musi być możliwość automatycznego wykrycia schematu i właściwej konstrukcji gladiatora
- Po czym na bazie wybranych przez użytkownika metod oceny sędziowie określą, który gladiator otrzyma najwięcej punktów.
Ta aplikacja wykorzystuje różne zrosty Fabryk ze Strategiami.
Czyli mniej więcej taki przepływ:
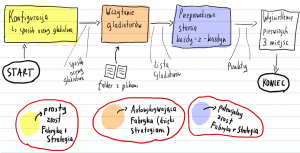
- W kolorze żółtym mamy do czynienia ze zwykłym zrostem fabryki i strategii.
- W kolorze pomarańczowym – fabryka, która ma kolekcję zarejestrowanych strategii i sama wybiera której strategii użyć w zależności od wejściowego pliku (czyli to, o co mnie poprosiliście na live).
- W kolorze niebieskim – miejsce, w którym potencjalnie można użyć strategii, by wprowadzić warianty i rozłączność (poza zakresem tego artykułu).
A w kodzie wygląda to tak:
Przełożenie danych (różne pliki wejściowe w różnych schematach) na klasę Competitor (czyli nasz Gladiator Henstagrama) wygląda w taki sposób:
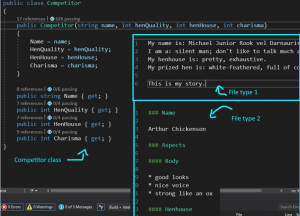
Czyli te dwa różne pliki po prawej stronie w dwóch różnych schematach mapują się na klasę po lewej stronie.
Cały kod jest dostępny w repozytorium na gitlabie pod linkiem: https://gitlab.com/completrics-public/henstagram-wars/-/tree/master/HenstagramWars
Nie musicie tam wchodzić; będę tłumaczył co się tam dzieje używając screenshotów. Acz jeśli chcecie zobaczyć całokształt i sobie uruchomić ów program, zapraszam.
Na początku – zacznijmy od klasycznego zrostu fabryki ze strategią
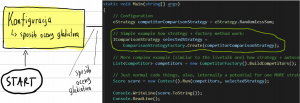
Wpierw – co to jest fabryka?
Czym – jako wzorzec projektowy – jest fabryka?
Z perspektywy analogii do świata rzeczywistego, to trochę tak jak gdybyście poszli do restauracji:
- Podajecie kelnerowi stringa „wątróbka z jabłkiem” i w odpowiedzi dostajecie obiekt obiadu zawierający wątróbkę, jabłko i być może ziemniaki.
- Podajecie kelnerowi stringa „żurek” i w odpowiedzi dostajecie obiekt obiadu zawierający żurek.
Fabryka to outsourcing konstruktora. Odpowiada za to, by:
- Prawidłowo zbudować obiekt w zależności od oczekiwań
- Prawidłowo skonfigurować obiekt
- Przejąć na siebie walidację danych wejściowych
- Przejąć na siebie skomplikowane budowanie obiektu
Czyli fabryka – w zależności od tego o co poprosimy – zbuduje nam odpowiedni obiekt i odpowiada za to, by był poprawnie skonstruowany i zwalidowany.
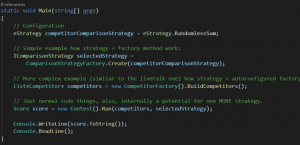
W kodzie nasza fabryka wygląda w taki sposób:
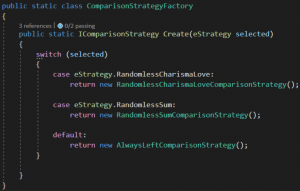
Innymi słowy, w zależności od tego o jaki komparator (IComparisonStrategy) poprosimy naszą fabrykę, zwróci nam poprawną:
- Jeśli poproszę o „RandomlessCharismaLove”, dostanę obiekt typu „RandomlessCharismaLoveComparisonStrategy”
- Jeśli poproszę o „RandomlessSum”, dostanę obiekt typu „RandomlessSumComparisonStrategy”
Niezbyt skomplikowane, prawda? Zbuduj odpowiedni obiekt w zależności od wymagań z zewnątrz.
No dobrze – czym jest strategia?
Dla przykładu ze świata rzeczywistego, jakie mamy strategie zdobycia obiadu?
- Strategia 1: zrobię obiad
- Strategia 2: zamówię obiad
- Strategia 3: poproszę żonę, żeby zrobiła mi obiad
Wszystkie trzy strategie mają te same parametry na wejściu i wyjściu (m.in. na wyjściu powinny kończyć się obiadem). Jednak każda z tych strategii realizowana jest inaczej.
Czyli strategia to wariant („zrób to samo w inny sposób”), alternatywny sposób zrobienia tej samej rzeczy. Ten wzorzec projektowy odpowiada za to, by:
- Umożliwić wymienność rozwiązań
- Wyizolować każdy wariant rozwiązania do osobnego miejsca
- Dać opcję łatwego dodawania nowych wariantów rozwiązań
Teraz spójrzmy na kod:
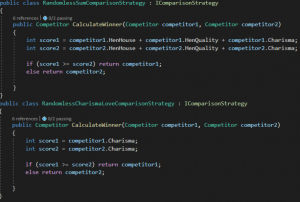
Mamy powyżej dwie strategie sędziowania gladiatorów. Każda z nich posiada metodę CalculateWinner, ale ta metoda realizowana jest w inny sposób:
- RandomlessSumComparison: sumuje wszystkie cechy gladiatora i określa jako zwycięzcę tego gladiatora, który ma wyższą sumę tych cech.
- RandomlessCharismaLove: patrzy tylko na jedną cechę – charyzmę. Ten gladiator, który ma wyższą charyzmę, ten wygrywa.
Czyli jeśli mamy dwóch gladiatorów:
- Adam (5, 4, charisma:2) -> suma 11, charyzma 2
- Barbara (3, 3, charisma:3) -> suma 9, charyzma 3
To RandomlessSumComparison uzna, że zwyciężył Adam a RandomlessCharismaLove uzna, że zwyciężyła Barbara.
Jak więc widzicie, obie strategie robią to samo (porównywanie który z dwóch gladiatorów jest wyżej), ale w inny sposób (jedna patrzy z perspektywy sumy cech, druga z perspektywy samej charyzmy).
Czemu ten prosty zrost fabryki i strategii jest przydatny?
Spójrzmy jeszcze raz na wykorzystanie tego kodu:
- Nieważne, jaką strategię wybiorę z perspektywy algorytmu wysokopoziomowego który widzicie na rysunku powyżej, za każdym razem to zadziała.
- Mogę spokojnie dodać nowy typ strategii do fabryki (tam gdzie jest ów switch) i nadal wszystko będzie funkcjonowało poprawnie. Czyli mam łatwą rozszerzalność kodu.
- Mogę testować każdą strategię z osobna, wszystko mam mocno wyizolowane:

Nie przez przypadek taki zrost Metody Fabrycznej i Strategii jak powyżej to jeden z najczęściej pojawiających się zrostów – ma bardzo mało niepożądanych efektów ubocznych i pozwala na wyizolowanie jednego miejsca na kreację obiektów.
Dobrze. Chodźmy do ciekawszego wariantu – jak zrobić fabrykę, która sama identyfikuje której strategii parsowania powinna użyć.
Ciekawszy wariant zrostu
Definicja problemu
Dla przypomnienia, jesteśmy tu:
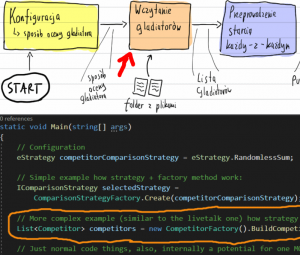
Obiecałem Wam fabrykę, która sama rozpoznaje z którym plikiem ma do czynienia i odpowiednio buduje obiekt Competitor. Ale na czym polega problem? Spójrzmy na dwa potencjalne schematy, z których składamy Gladiatora:
- Nasz Competitor ma cztery pola: Name, HenQuality, Henhouse, Charisma.
- Jeden schemat używa:
- My name is: <ważny tekst>
- I am a: <ważny tekst>
- …
- Drugi schemat używa klasycznego markdowna z podziałem na headery (### xxx) i listę (* xxxx).
I załóżmy teraz, że mając powyższe dane – przykładowo, 100 plików – chcemy zrobić tak, by nasza fabryka sama decydowała w jaki sposób wyciągnąć dane z plików po prawej do obiektu Competitor.
Jak to ruszyć?
Rozwiązanie, część 1: parsowanie różnych plików
Mamy różne schematy plików. Chcemy wykonać tą samą operację – parsowanie – na różne sposoby, w zależności od tego w jakim schemacie mamy dane pliki. Czy to się Wam z czymś kojarzy?
Strategia.
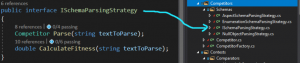
Czyli nasza fabryka (CompetitorFactory) wykorzystuje jeden z parserów (AspectSchemaParsingStrategy lub EnumerationSchemaParsingStrategy). A nasze strategie mają po dwie metody: Parse lub CalculateFitness.
Na razie skupmy się jednak tylko na pierwszej metodzie, Parse. Jak to zaimplementować?
Weźmy przykład schematu opartego o Aspekty i czysty markdown:
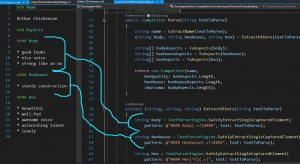
Po lewej stronie powyżej widzicie zawartość pliku, po prawej widzicie jak jest parsowany:
- Używając wyrażeń regularnych znajdź tekst od „#### Body” do następnego „####”, po czym wyciągnij to co tam jest pod spodem
- Następnie przekształć tamten tekst w listę aspektów (fraz typu „good looks”)
- Następnie policz, ile takich aspektów jest na liście. Ta ilość to nasza kategoria (tu: Body mapuje się na Charisma)
Same szczegóły parsowania nie mają tu znaczenia; macie dostęp do kodu a wyrażenia regularne odbierają 10 punktów poczytalności jak się na nie patrzy.
To, co tu jest ważne – widzicie tu jedną strategię parsowania plików typu AspectSchema.
Dla porównania, druga strategia parsowania plików typu EnumerationSchema:
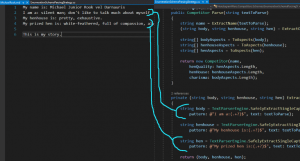
- Używając wyrażeń regularnych znajdź tekst od „I am a:” do końca linijki, po czym go wyciągnij
- Następnie podziel wynik po przecinku na aspekty („pretty, exhaustive” -> [„pretty”, „exhaustive”])
- Następnie policz, ile takich aspektów jest na liście. Ta ilość to nasza kategoria (tu: Body mapuje się na Charisma)
Podejrzewam, że widzicie zarówno duże podobieństwa w strukturze kodu obu strategii, jak i zdecydowane różnice (szukają innych wzorów w tekście).
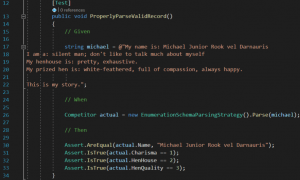
Zauważcie, że bardzo łatwo można napisać test sprawdzający czy nasza strategia parsowania działa, w izolacji od reszty aplikacji:
Rozwiązanie, część 2: rejestracja strategii w fabryce
Mamy więc nasze strategie, które prawidłowo parsują odpowiednie pliki. Ale w jaki sposób sprawić, by te strategie były faktycznie wykorzystane w kodzie fabryki?
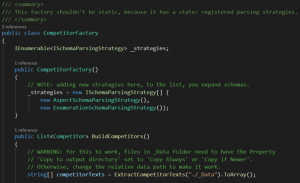
Mamy listę potencjalnych strategii, których możemy użyć. I w konstruktorze CompetitorFactory dodajemy wszystkie strategie, które chcemy obsługiwać.
Następnie w metodzie BuildCompetitors chcemy przypisać odpowiednią strategię do pliku w taki sposób, by odpowiednia strategia sparsowała odpowiedni plik.
Zauważyliście, jak łatwo jest dodać nowy format schematu do takiego zrostu strategii i fabryki?
- Dodajecie nowy obiekt strategii odpowiadający nowemu schematowi
- Zapewniacie, by obiekt strategii miał te same metody i te same wejścia i wyjścia w metodach
- Dodajecie ten obiekt strategii do powyższej listy w fabryce
- Wszystko działa. Brak dodatkowej ingerencji w kod. Nowy schemat -> dodanie nowej strategii parsowania do listy w fabryce. Skasowanie schematu -> usunięcie jednej strategii parsowania z tej listy.
Ale jak sprawić, by „właściwa” strategia parsowała „właściwy” plik?
Rozwiązanie, część 3: którą strategią sparsować ten plik?
Fitness function, lub funkcja dopasowania. Skąd my – ludzie – wiemy której strategii użyć do parsowania tych plików? Patrzymy na wzór i „który sposób parsowania najbardziej pasuje”.
Dokładnie ten sam mechanizm występuje w naszych strategiach parsowania. To jest ta druga funkcja znajdująca się w strategii, CalculateFitness.
Popatrzmy na test demonstrujący to zjawisko:
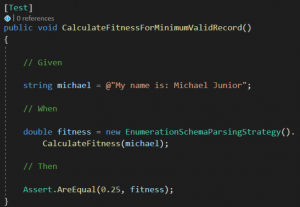
Nasz Gladiator ma cztery parametry: Name, Hen, Henhouse, Charisma. W wypadku powyższego testu jedynie jeden parametr udało się poprawnie sparsować: Name. Tak więc z czterech parametrów udało się nam sparsować jeden parametr. Dopasowanie (fitness) wynosi więc 1/4, czyli 0.25.
Innymi słowy, na czym polega sprawdzenie, która strategia powinna sparsować dany plik?
- Rzucamy wszystkie strategie na każdy plik obliczając Dopasowanie
- Wybieramy tą strategię, która ma najwyższe Dopasowanie i tylko tą strategią parsujemy dany plik
- Jeśli plik jest uszkodzony (żadna strategia sobie nie radzi), nie dodajemy Gladiatora do listy.
I teraz mogę pokazać dokładnie ten mechanizm w kodzie fabryki:
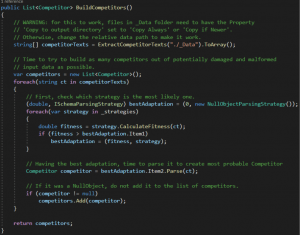
Czyli, idąc jeszcze raz za powyższym algorytmem:
- Nasza fabryka nie buduje jednego Gladiatora – buduje kolekcję Gladiatorów.
- Z podanego folderu (tu: „./Data”) wczytaj wszystkie zawartości w formie tekstu, takiego jak w testach które pokazywałem powyżej.
- Dla każdego tekstu wykonaj wszystkie operacje:
- Rzuć na tekst wszystkie strategie, znajdź najlepszą
- Po znalezieniu najlepszej strategii, sparsuj tekst ową strategią
- Jeśli to null, nie dodawaj tego do kolekcji.
Zauważcie, że dzięki temu że pracuję na kolekcjach a nie pojedynczych plikach to nie mam połowy problemów wynikających z „if null”. Kolekcja nullem nigdy nie będzie, mogę najwyżej mieć listę bez ani jednego elementu w środku.
Ten zrost fabryki i strategii jest bardziej skomplikowany niż poprzedni.
Ten odpowiada za prawidłową konstrukcję i konfigurację kolekcji obiektów typu Competitor na bazie nieoznaczonych danych zewnętrznych. A bardzo często budowanie obiektów wymaga dużej ilości zachodu, korzystania z innych usług (service) i ratowania się wartościami domyślnymi (default).
Gdybym konstrukcję obiektu Competitor miał w konstruktorze, dość ciężko byłoby poradzić sobie z uszkodzonym plikiem – jesteś w środku konstruktora i nie możesz zbudować obiektu: co robisz?. Może wyjątek? 😉
A tak, dzięki użyciu fabryki konfigurującej listę Competitorów – mam gwarancję, że każdy Competitor jest dobrze zbudowany, przeszedł walidację (i łatwo zbudować go do testów innych fragmentów systemu):
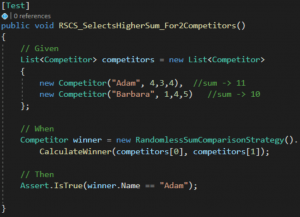
(Wyobraźcie sobie, że w powyższym kodzie do zbudowania Competitora potrzebny mi jest plik tekstowy i cała ta magia budująca będzie miała miejsce w konstruktorze a nie w fabryce. Niefortunne, nie? No i troszkę trudniej zbudować test.)
Podsumowując
Fabryka – odpowiada za właściwą konstrukcję i konfigurację budowanego obiektu.
Strategia – odpowiada za robienie „tego samego” w „inny sposób”.
Zrost fabryki i strategii daje dzięki temu całkiem sporo możliwości.
Klasyczny zrost (prosty, taki jak ten dla strategii sędziowania / porównywania gladiatorów) pozwala Wam na:
- Łatwą testowalność każdej strategii z osobna
- Łatwe dodanie nowej strategii by cały system z nią działał (przez dodanie do fabryki)
- Kod budowy obiektu (często trudny i nieporęczny) jest w innym miejscu niż kod „biznesowy” obiektu, dzięki czemu nie mamy zaśmieconego kodu konstrukcją
Bardziej zaawansowany zrost, jak ten dla strategii parsowania pozwala Wam na:
- Automatyczne wykrycie typu obiektu przy użyciu zarejestrowanej strategii
- Dynamiczne dodawanie i odejmowanie strategii parsowania do fabryki, w trakcie działania programu, przez modyfikację listy (tu niepotrzebne, ale może się przydać np. jeśli włączysz DLC w grze komputerowej)
Swoją drogą, zdecydowanie nie polecam wykorzystywania tego bardziej zaawansowanego zrostu jeśli nie macie problemu który tego wymaga. Im kod prostszy i czytelniejszy, tym lepiej.
Chciałbym jednak, byście zobaczyli, że zrost tych samych wzorców projektowych może mieć zupełnie inne implementacje w zależności od potrzeb i że to nie zawsze wygląda identycznie.





{kind=link}